TL; DR Want to reduce the noise and focus on the interested content? There is the new project "Auto-News" which integrates with LLM to help you. This is the first article, I will mainly cover about the high ideas/architecture/solution and post more in the future.
Motivation
In the world of this information explosion, we live with noise every day, it becomes even worse after the generative AI was born. Think about how much time we spent on pulling/searching/filtering content from different sources, how many times we put the article/paper or long video as a side tab, but never got a chance to look at, and how many efforts to organize the information we have read. We need a better way to get rid of the noises, and focus on reading the information efficient based on the interests, and stay on the track of the goals we defined.
Goals
Time is the precious resource for each of us, to overcome/mitigate above noises, something I really wish to have:
- Automatically pull feed sources, including RSS, Tweets.
- Support clip content from source directly, later generate summary and translation, including random web articles, YouTube videos
- Filter content based on personal interests and remove 80%+ noises
- A unified/central reading experience (e.g. RSS reader Feedly, Notion-based)
- Weekly/Monthly top-k aggregations
Problem Statement
There are too many different information sources, such as Web articles/subscriptions, YouTube Videos, Reddit, Twitter, RSS, etc.
- Some of them have the recommendation system already which can push the information based on our own interests (e.g. YouTube, Twitter)
- But most of them are not (e.g. RSS, Reddit, Web articles)
Notes: Even the system with recommendation model, roughly 30% of the information are relevant.
To aggregate all the above information proactively, based on our own interests timely, we have the following problems to deal with:
- Lack of a "good" aggregator to fetch and filter all the sources
- Lack of an easy-to-use system to summarize and translate the source, especially for the long article and video (Some videos have no transcript)
- Lack of low-cost system to help us build the product which connect to the sources and expert agents. E.g. Zapier/Make is the automation platform, but it’s costly and still need some efforts to build and tune
Solution
Instead of build a costly solution on top of Zapier/Make and with many limitations, I decided to build one which connect to:
- Sources: RSS, YouTube, Article, Tweets (covers 80%+ use cases)
- LLM Agents: OpenAI-ChatGPT, OpenAI-Whisper, HuggingFace Embedding
- Databases: MySQL, Milvus, Redis, etc
- Orchestration: Airflow, Langchain
- UI: Notion
For content recommendation, we also need a feedback loop to allow user giving the rating for a content, then we can use this rating to further predict the similar content’s rating
Architecture
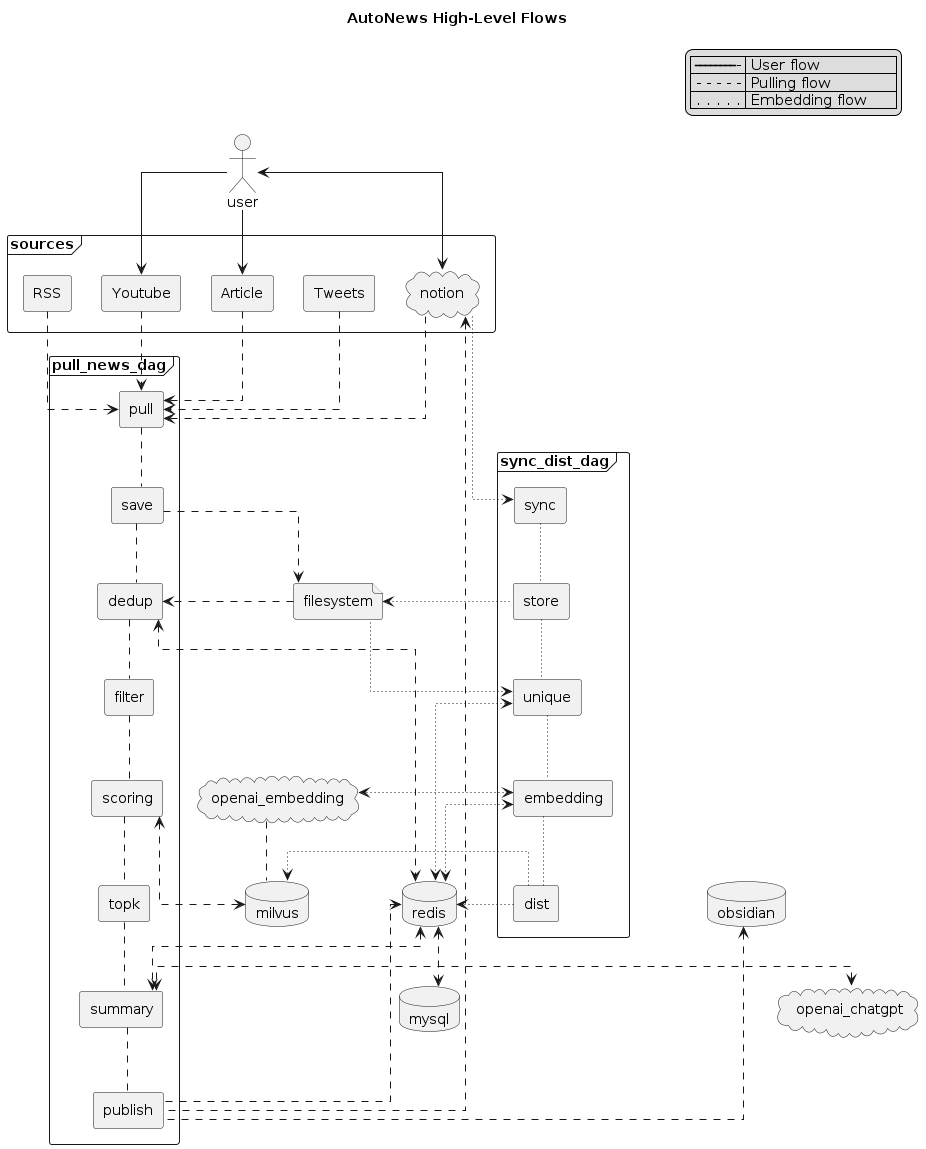
User Experiences
Collection flow
- [User] save articles into
Article Inbox - [User] save YouTube videos into
Youtube Inbox - [System]:
- Pulls Tweets/RSS automatically and periodically (every 1 hour)
- Scoring on the new content according to the embedding results + KNN algo
- Speech to text if video has no transcript provided
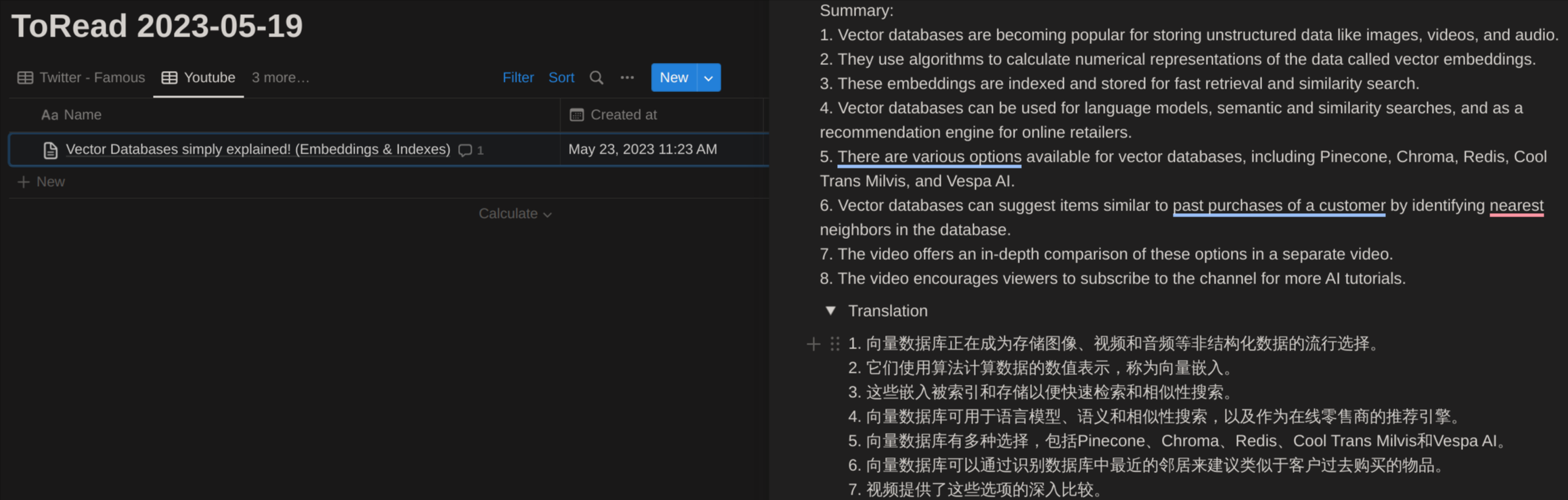
- Summarize and translate the content
Reading flow
- [User] read Tweets/Articles/YouTube Videos from
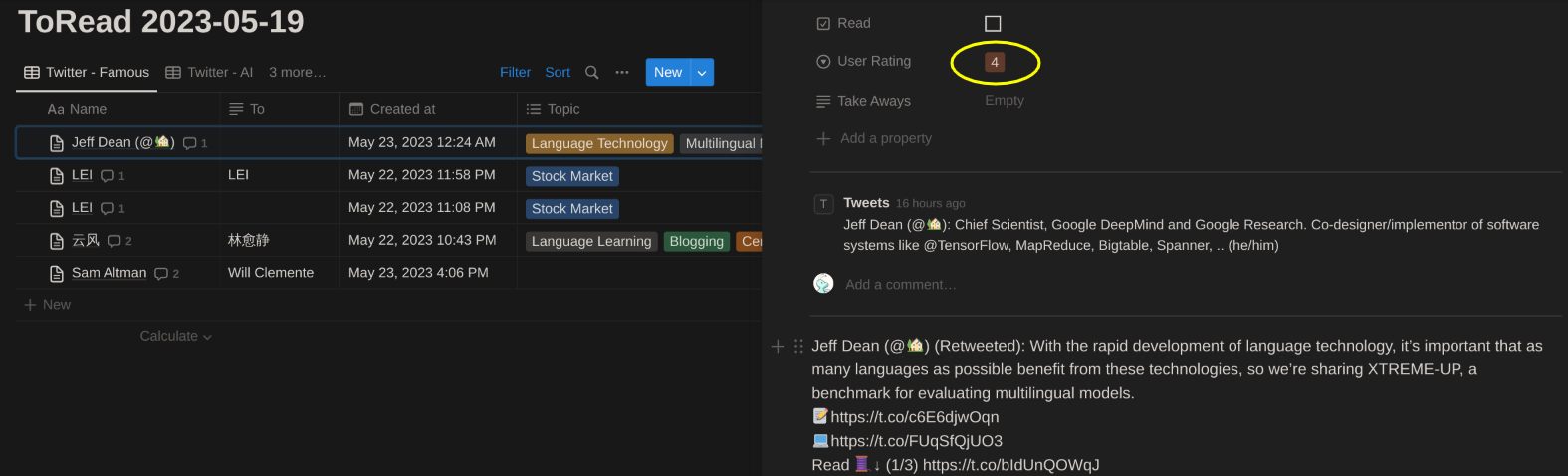
ToReadpage - [User] gives the rating if needed (1-5, the higher the better)
Embedding flow
- [System] syncs the pages with non-empty user rating, do text embedding and store into vector database
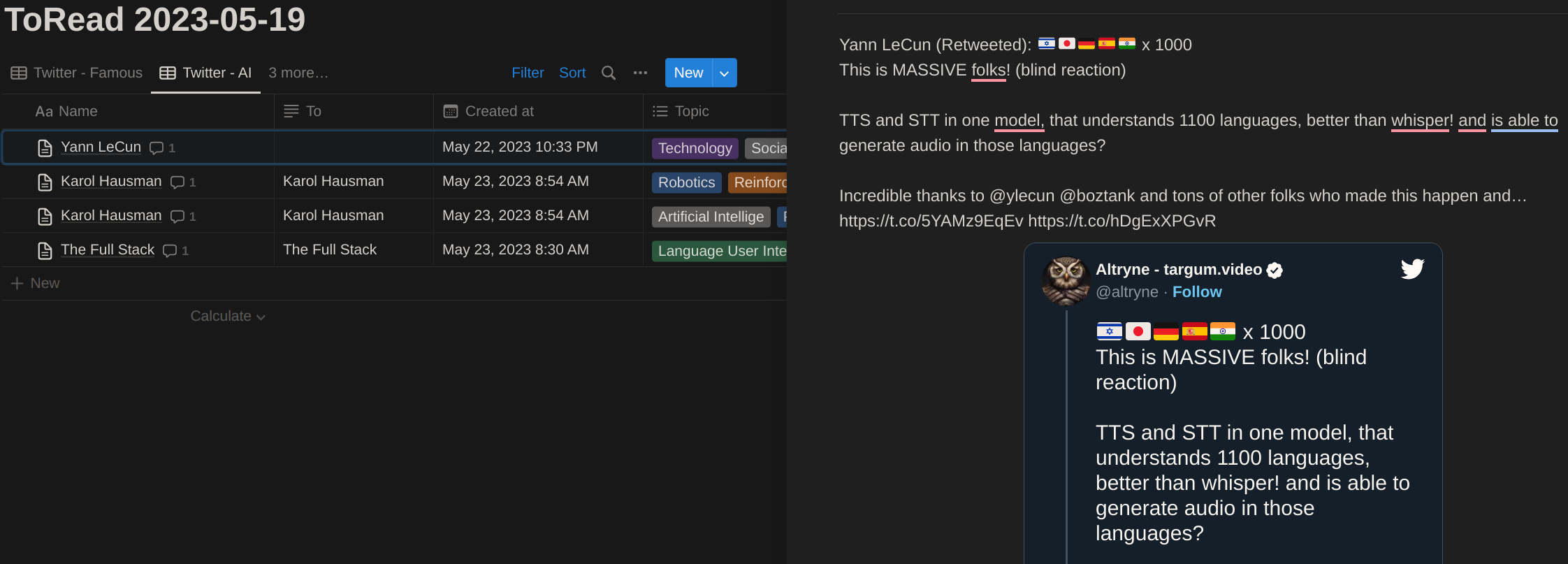
Screenshoots

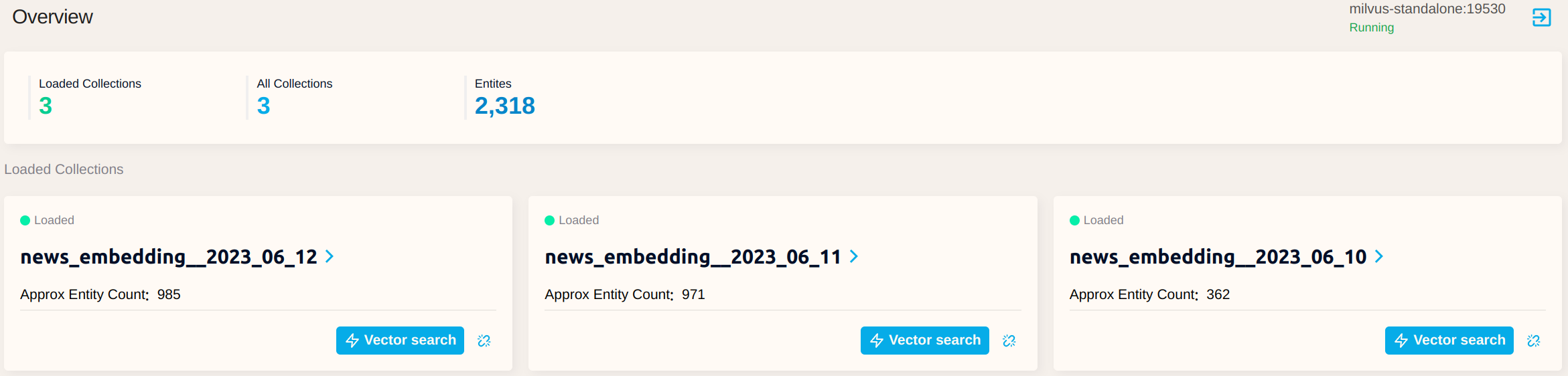
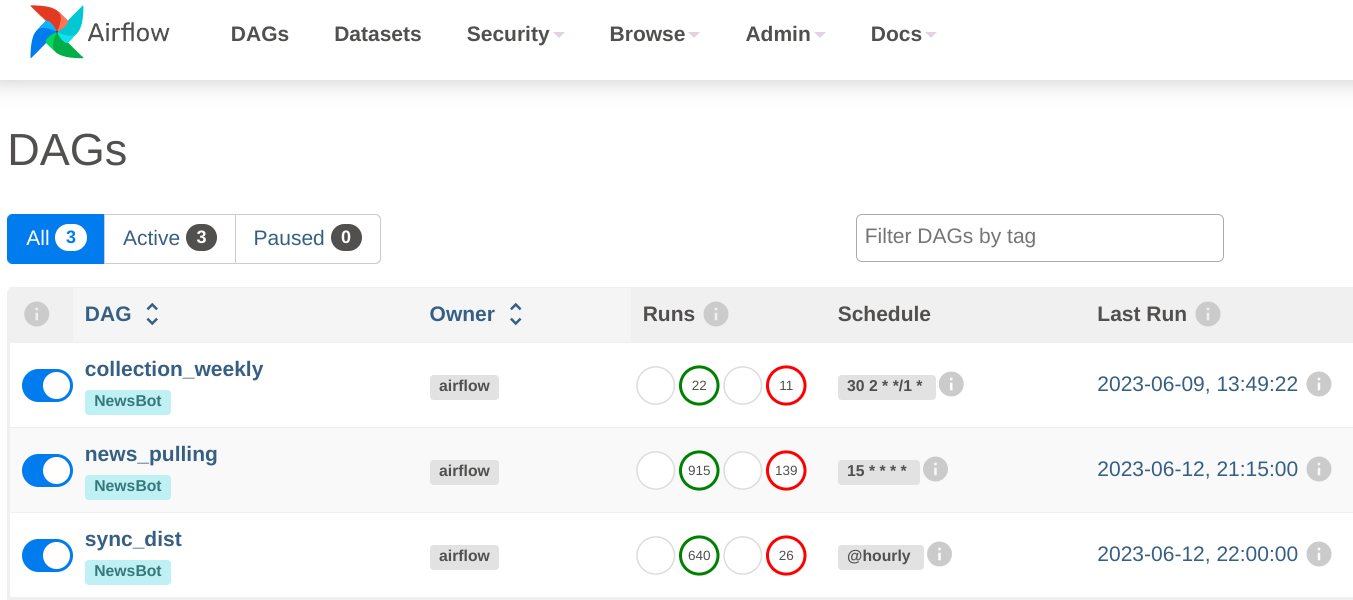
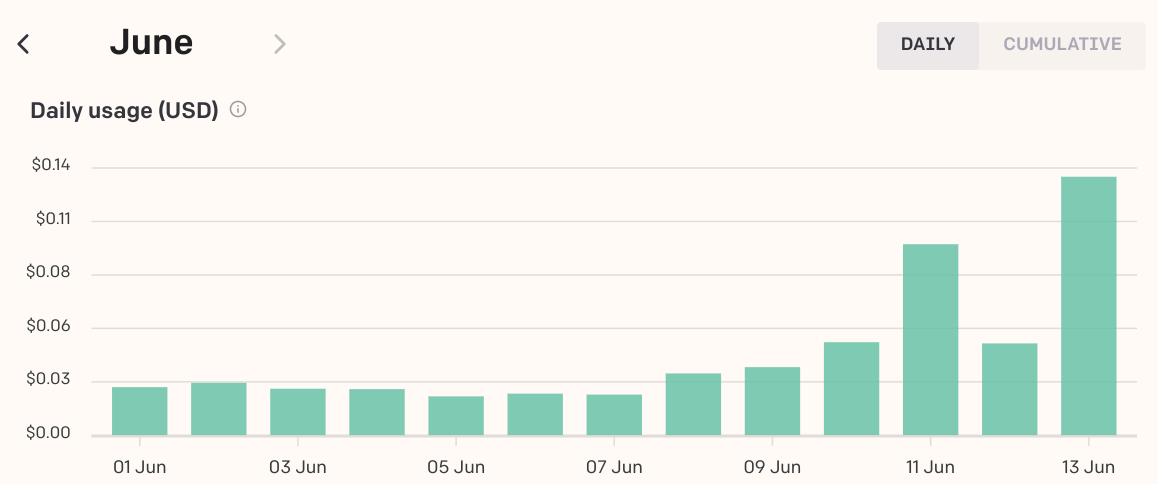
Billing Usage
Example of using openAI:
Next
- Top-k Weekly, Monthly, Yearly summary on what we have read
- Use local embedding model instead of OpenAI Embedding model (save cost) if accuracy rate is high enough
- Use local LLM instead of OpenAI ChatGPT (save cost) if accuracy rate is high enough
Where to get it?
If you read here, have interests and want a try, here is the code repo on the github, since this is the early version, and a lot of enhancements on the road, feel free to open an issue/PR on the github.
In the next few posts, I’ll talk about the UI setup, backend installation, design details, etc, stay tuned.